exoticspice1
Site Champ
- Joined
- Jul 19, 2022
- Posts
- 457
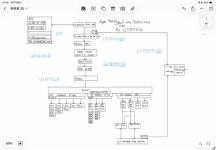
M5 P core:

M5 M core:

M5 E core:

SPEC CPU 2017 details on M cores:

sourced from Baidu.
M5 M core:
M5 E core:
SPEC CPU 2017 details on M cores:
sourced from Baidu.

")