You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
M3 core counts and performance
- Thread starter Cmaier
- Start date
")
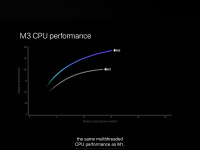
But Apple's graph shows power consumption for the whole CPU. Not just one core. One core consumes about 5W in single threaded operation on M3 and about 4W on M1 according to powermetrics.After posting the Apple CPU and GPU performance vs. power graphs, it occured to me it might be fun to digitize one of them and see what scaling they showed. I thus digitized the M3 CPU plot using https://plotdigitizer.com/app (the white dots indicate where I placed points):
View attachment 27382
As this curve is for a single core, I associated the highest performance score with the max clock I've seen (4.06 GHz) and scaled all other performance scores correspondingly, to translate them into clock speeds as well. I then transposed the data into the form power vs. clock speed (i.e., switching the x and y axes), and fit it to a three-parameter polynomial. Finally I compared the curve Apple is showing, to the one I fit using the data @leman collected for the A17 performance core.
Apple's curve is steeper. The best fit I got for leman's data was with a polynomial of the form a + bx^2+cx^6, while the best fit for Apple's curve was obtained using one of the form a + bx^2+cx^8.
[Note this doesn't mean the scaling goes as x^6 and x^8, respectively. It's nowhere near that strong, as the value of c is far smaller than b, in both cases. Specifically, based on the relative sizes of the coefficients, the scaling has 99.74% x^2 character and 0.26% x^6 character for leman's, and 99.99% x^2 and 0.01% x^8 for Apple's.]
Here's a plot comparing the two:
View attachment 27384
There is a big difference in wattage. If we extrapolate Leman's A17 data to 4.06 GHz, we get 6.5 W, as compared with the 15.2 W for 4.06 GHz in Apple's M3 curve. Was Apple being conservative in presenting its power figures or scaling?, I.e., were they including more than just the pure CPU power consumption so they would not be accused of under-reporting it, and/or were they over-stating how steep the power curve would be?
Or do the M3 P cores consume more power than the A17's at the same clock? At least on GB6, they shouldn't, since the M3 P cores do perform like A17 P cores run at higher clocks—they extrapolate to a GB6 score of 3116 at 4.06 GHz: 4060/3780 *2901 = 3116. This falls within the range of scores Primate lists for the M3 (2955 to 3127).
View attachment 27385
Finally, if we take Apple's M3 curve and extrapolate to a 10% increase in clock speed (4.66 GHz), we get an 80% increase in wattage (27.4 W). Too much for an MBP, but not an issue for the Studio, especially if they use stronger dynamic frequency scaling, i.e., a stronger % frequency reduction as more cores are loaded (hint, hint Apple).
View attachment 27386
8:54 Johnny says multi threaded performance.
Attachments
But Apple's graph shows power consumption for the whole CPU. Not just one core. One core consumes about 5W in single threaded operation on M3 and about 4W on M1 according to powermetrics.
8:54 Johnny says multi threaded performance.
Ah, thanks for the correction. Don't know how I got confused, since in my previous post about that graph I did indicate it was a multi-core value (https://techboards.net/threads/m3-core-counts-and-performance.4282/page-30#post-150123). Sigh—I forgot my own analysis! Anyways, I will update my post!
Last edited:
Forget LPDDR5X. This is what Apple should be using in its Macs:
[Assuming we're not going to seeing HBM3E...]
AnandTech Forums: Technology, Hardware, Software, and Deals
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
www.anandtech.com
Seems Micron’s 9600 version still falls within the LPDDR5X spec but yes either would be neat in next year’s release. We can cross fingers for it to show up in M3 Ultra (if it is redesigned and not 2 M3 Maxes though even then standard 5X is more likely) but such memory is more likely in A18/M4.Forget LPDDR5X. This is what Apple should be using in its Macs:
[Assuming we're not going to seeing HBM3E...]AnandTech Forums: Technology, Hardware, Software, and Deals
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.www.anandtech.com
Forget LPDDR5X. This is what Apple should be using in its Macs:
[Assuming we're not going to seeing HBM3E...]AnandTech Forums: Technology, Hardware, Software, and Deals
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.www.anandtech.com
Would be great, but can SK Hynix ship quantities Apple needs?
Aaronage
Power User
- Joined
- Feb 26, 2023
- Posts
- 144
Sorry to go off topic, only tangentially related
I saw this leak about Intel Lunar Lake https://videocardz.com/newz/intel-l...res-tsmc-n3b-node-and-displayport-2-1-support
It’s kinda funny? It’s basically “Intel does an M1”, but they’ve managed to make it horrendously complex (Foveros, split compute/SoC dies, Thread Director etc.) and very late (planned for 2025).
I’m fascinated by how often Intel finds convoluted solutions to problems.
I watched the interview with Dave Cutler on Dave’s Garage a few days back. What’s striking is how often Cutler says something along the lines of “Intel kept sending us overly complex, broken hardware”. Everything I’ve read/heard about Intel over the years has followed that pattern - just no end of bad engineering and/or bad management.
I saw this leak about Intel Lunar Lake https://videocardz.com/newz/intel-l...res-tsmc-n3b-node-and-displayport-2-1-support
It’s kinda funny? It’s basically “Intel does an M1”, but they’ve managed to make it horrendously complex (Foveros, split compute/SoC dies, Thread Director etc.) and very late (planned for 2025).
I’m fascinated by how often Intel finds convoluted solutions to problems.
I watched the interview with Dave Cutler on Dave’s Garage a few days back. What’s striking is how often Cutler says something along the lines of “Intel kept sending us overly complex, broken hardware”. Everything I’ve read/heard about Intel over the years has followed that pattern - just no end of bad engineering and/or bad management.
In fairness some of that is stuff Apple may yet pursue or doesn’t have to because they control the thread scheduling process. While it might seem overkill for an M1 equivalent, separating dies has advantages like being able to package different parts potentially fabricated with different nodes and mixing and matching like Legos for different target audiences. Imagine if you will a M3 Max CPU with an M3 GPU for people uninterested in gaming or GPU power but needing a lot of CPU power or the opposite for gamers, an M3 CPU with an M3 Max GPU, etc … Building such a variety of systems with a unified SOC would be prohibitively expensive, packaging different components together can make it more practical. Obviously that’s more of a focus of Intel since they serve so many different markets, but even for Apple I believe the approach would have merit.Sorry to go off topic, only tangentially related
I saw this leak about Intel Lunar Lake https://videocardz.com/newz/intel-l...res-tsmc-n3b-node-and-displayport-2-1-support
It’s kinda funny? It’s basically “Intel does an M1”, but they’ve managed to make it horrendously complex (Foveros, split compute/SoC dies, Thread Director etc.) and very late (planned for 2025).
I’m fascinated by how often Intel finds convoluted solutions to problems.
I watched the interview with Dave Cutler on Dave’s Garage a few days back. What’s striking is how often Cutler says something along the lines of “Intel kept sending us overly complex, broken hardware”. Everything I’ve read/heard about Intel over the years has followed that pattern - just no end of bad engineering and/or bad management.
exoticspice1
Site Champ
- Joined
- Jul 19, 2022
- Posts
- 457
If they reserve it only for the M3 Pro and M3 Max. Yep, they sure can.Would be great, but can SK Hynix ship quantities Apple needs?
Aaronage
Power User
- Joined
- Feb 26, 2023
- Posts
- 144
I appreciate there are benefits to disaggregated/“chiplet” designs. I like what AMD, Amazon etc. are doing with that, and I could absolutely see Apple dabbling in that in the future. I’m just struggling to find the point in this particular case.In fairness some of that is stuff Apple may yet pursue or doesn’t have to because they control the thread scheduling process. While it might seem overkill for an M1 equivalent, separating dies has advantages like being able to package different parts potentially fabricated with different nodes and mixing and matching like Legos for different target audiences. Imagine if you will a M3 Max CPU with an M3 GPU for people uninterested in gaming or GPU power but needing a lot of CPU power or the opposite for gamers, an M3 CPU with an M3 Max GPU, etc … Building such a variety of systems with a unified SOC would be prohibitively expensive, packaging different components together can make it more practical. Obviously that’s more of a focus of Intel since they serve so many different markets, but even for Apple I believe the approach would have merit.
Like, AMD’s strategy makes a whole lot of sense. Chiplets are primarily used to achieve scalability and flexibility in the server space (with Epyc and Instinct). It’s just a nice bonus that e.g. Epyc CCD scraps also make for great desktop CPUs. For mobile, AMD is still going with reasonably sized monolithic dies.
Lunar Lake appears to be using a special compute die (4P+4E and small GPU/NPU - not scalable) paired to a seemingly special SoC die (limited IO, no “SoC cores” like Meteor Lake etc.). The core counts are low enough that you’d expect the die size for a monolithic part to be quite small. So why go with special dies and exotic packaging here? There must be some logic to that decision, but it looks weird to an outsider (and compared to M3, X Elite, Ryzen mobile etc.)

If what you say is accurate, then practice. Intel did the same with their first mixed core designs known as Lakefield. It was an incredibly limited SOC, on a limited run, limited use case product that no one actually wanted to buy other than a curiosity, but was the predecessor for getting Alder Lake working (mostly) correctly.I appreciate there are benefits to disaggregated/“chiplet” designs. I like what AMD, Amazon etc. are doing with that, and I could absolutely see Apple dabbling in that in the future. I’m just struggling to find the point in this particular case.
Like, AMD’s strategy makes a whole lot of sense. Chiplets are primarily used to achieve scalability and flexibility in the server space (with Epyc and Instinct). It’s just a nice bonus that e.g. Epyc CCD scraps also make for great desktop CPUs. For mobile, AMD is still going with reasonably sized monolithic dies.
Lunar Lake appears to be using a special compute die (4P+4E and small GPU/NPU - not scalable) paired to a seemingly special SoC die (limited IO, no “SoC cores” like Meteor Lake etc.). The core counts are low enough that you’d expect the die size for a monolithic part to be quite small. So why go with special dies and exotic packaging here? There must be some logic to that decision, but it looks weird to an outsider (and compared to M3, X Elite, Ryzen mobile etc.)
Edit: Also cost, the SOC die is mostly IO and I don't see the fabrication node for it (most Lunar Lake CPUs will be "Intel 18" except Lunar Mx which will be TSMC N3B). My guess is since IO doesn't benefit from node shrinkages you can get costs down by putting that into its own tile and then simply reusing that tile over and over and over again across multiple products and generations. AMD talked about that with the disaggregated GPU design and the purpose of excising the IO. Anything you don't have to redesign every generation is a win. This may be the start of that for Intel.
Last edited:
Yoused
up
- Joined
- Aug 14, 2020
- Posts
- 8,538
- Solutions
- 1
Well, the underlying premise of modular builds is that die components can be selected for good units and put together to form a complete, fully-functional product. That is, assuming the post-burn interconnetion is 100% reliable. And maybe the interconnect will not cost significantly more in performance than a tailored monolithic die. And maybe more components can be fit onto a wafer than individual monolithic dies. It all sounds so appealing. Apple is not doing this for some reason. I would guess they have done the math and concluded that binning works about as well, even on the somewhat iffy N3B process.
Would be great, but can SK Hynix ship quantities Apple needs?
According to their press release, Hynix is using using an "HKMG (High-K Metal Gate)" implementation on "1anm", which is their 4th-gen 10nm process. However, in looking at their press releases from a year or two ago, those are identical to what it has been using for LPDDR5X. Thus it looks like a new architecture/settings applied to a mature process. Speculating, it may come down to the fraction of the chips they produce with that process that is able to meet these new specs.If they reserve it only for the M3 Pro and M3 Max. Yep, they sure can.
Another interesting question is whether the existing M3 chips could accommodate a new generation of RAM (either LPDDR5X or 5T)—or if this would need to wait for M4. Intel has manufactured CPUs that can accommodate two different RAM generations (DDR4 & DDR5), so perhaps Apple could have designed its M3's to accommodate two gens as well.
Last edited:
B01L
SlackMaster
- Joined
- Dec 1, 2021
- Posts
- 210
If the on-die memory controllers can handle the faster speed (and larger capacities), LPDDR5X is pin-compatible with LPDDR5, so it should be a straight drop-in replacement...?
A (hypothetical) Mn Extreme SoC configuration (if using an in-line scheme) could have up to 960GB of ECC LPDDR5X RAM (with 2TB/s UMA bandwidth)...?
A (hypothetical) Mn Extreme SoC configuration (if using an in-line scheme) could have up to 960GB of ECC LPDDR5X RAM (with 2TB/s UMA bandwidth)...?
According to their press release, Hynix is using using an "HKMG (High-K Metal Gate)" implementation on "1anm", which is their 4th-gen 10nm process. However, in looking at their press releases from a year or two ago, those are identical to what it has been using for LPDDR5X. Thus it looks like a new architecture/settings applied to a mature process. Speculating, it may come down to the fraction of the chips they produce with that process that is able to meet these new specs.
Another interesting question is whether the existing M3 chips could accommodate a new generation of RAM (either LPDDR5X or 5T)—or if this would need to wait for M4. Intel has manufactured CPUs that can accommodate two different RAM generations (DDR4 & DDR5), so perhaps Apple could have designed its M3's to accommodate two gens as well.
Even if it weren’t a straight drop in with 5 we know that Apple changed the memory in the M1 generation from LPDDR4X to 5 starting with the Pro. Of course the Pro had a different memory controller and the Ultra likely won’t unless Apple has redesigned the Ultra to be its own SOC.If the on-die memory controllers can handle the faster speed (and larger capacities), LPDDR5X is pin-compatible with LPDDR5, so it should be a straight drop-in replacement...?
A (hypothetical) Mn Extreme SoC configuration (if using an in-line scheme) could have up to 960GB of ECC LPDDR5X RAM (with 2TB/s UMA bandwidth)...?
Truthfully while I expect Apple to offer LPDDR5X next year either with the Uktra or the M4, I’m cautious about them using the latest and fastest modules. They probably simply didn’t redesign the memory controller from the M2 to shorten development on the M3 (except on the Pro to narrow it) and allow them to hit their design schedule. So we again expect new memory controllers. And if they’re already hitting LPDDR5X these both look overall compatible so it’s definitely possible. I just don’t want to set that as the expectation even though Apple’s UMA design benefits from bandwidth greatly.
If they reserve it only for the M3 Pro and M3 Max. Yep, they sure can.
Did you mean M4?
4.06 GHz (maximum M3 SC clock)
leman's A17 data: 6.5 W
Apple's curve: 6.3 W
4.446 GHz (10% increase in clock over 4.06 GHz)
leman's A17 data: 9.3 W (43% increase in power consumption)
Apple's curve: 10.4 W (65% increase consumption)
So it seems a 10% increase in clock speed would cost us an ≈50% increase in power consumption. Still, the added wattage could certainly be handled by an M3 Studio (hint, hint Apple
I was wondering if Apple were to increase in power consumption on Studio chips whether a better approach might be to increase clocks on all core loads - you could probably increase multicore power consumption and get a lot more multicore performance, which is one of the main points of a Studio. Basically you get a lot better performance bang for your power buck than increasing maximum single core clocks. Of course they could do both, but I don’t think they’ll do either (again unless the ultra is a new SOC and not simply two Maxes then I can see them maybe increasing clocks very slightly a la the M2 generation) even though it’d be nice for desktop users to squeeze out more performance. Basically clocks seem to stay mostly steady across the lineup, it’s core counts that change, seems to be Apple’s approach.
Last edited:
Aaronage
Power User
- Joined
- Feb 26, 2023
- Posts
- 144
+1. I like the idea of letting Mac Studio run all cores at max boost (~4GHz) without increasing the max boost clock.I was wondering if Apple were to increase in power consumption on Studio chips whether a better approach might be to increase clocks on all core loads - you could probably increase multicore power consumption and get a lot more multicore performance, which is one of the main points of a Studio. Basically you get a lot better performance bang for your power buck than increasing maximum single core clocks. Of course they could do both, but I don’t think they’ll do either (again unless the ultra is a new SOC and not simply two Maxes then I can see them maybe increasing clocks very slightly a la the M2 generation) even though it’d be nice for desktop users to squeeze out more performance. Basically clocks seem to stay mostly steady across the lineup, it’s core counts that change, seems to be Apple’s approach.
Yeah I don’t know that they could run all cores at 4 though that’d be cool - but @Cmaier talks about how even if total power isn’t too bad, all the cores at full power might interfere with each other and create local hotspots. But I suspect they probably could run them at higher base clocks - especially in “high power mode”. What are the base clocks for M3? Has anyone made a clock stepping chart for M3/Pro/Max yet? I haven’t been able to find one.+1. I like the idea of letting Mac Studio run all cores at max boost (~4GHz) without increasing the max boost clock.
Nycturne
Elite Member
- Joined
- Nov 12, 2021
- Posts
- 1,784
In fairness some of that is stuff Apple may yet pursue or doesn’t have to because they control the thread scheduling process.
Honestly, I believe you want the thread scheduling as simple as possible. Complexity breeds errors. Thread Director attempts to infer things due to missing information from the executing threads about the semantics of those threads. Now, Thread Director also means the OS can evolve and play a bigger role in filling in that missing information in the long-run, but there’s also less incentive to do so if the inference logic works “well enough”.
Apple’s approach builds on thread priority tags that they introduced back in the Lion days. GCD and Swift Concurrency both use these tags, meaning there’s more than a decade of developer use and that use will continue into new forms of async logic on the platform. Something that I don’t think can be said about the Win32 environment. So I’m not really sure Apple has incentive to pursue the sort of things Intel/Windows is trying, because they’ve already spent a great deal of effort creating a platform that doesn’t need those things. That tag Apple relies on is the simplest core idea of the semantic information Windows has historically lacked, and they can build on it going forward if they wish.
Absolutely, that’s a more complete explanation of what I was trying to say in brief, perhaps too briefly: because they control the whole platform, Apple doesn’t require a complex thread director in their hardware. Again though, yours is a much more thorough description of how Apple achieves thread control without one and why Intel felt the need to include one.Honestly, I believe you want the thread scheduling as simple as possible. Complexity breeds errors. Thread Director attempts to infer things due to missing information from the executing threads about the semantics of those threads. Now, Thread Director also means the OS can evolve and play a bigger role in filling in that missing information in the long-run, but there’s also less incentive to do so if the inference logic works “well enough”.
Apple’s approach builds on thread priority tags that they introduced back in the Lion days. GCD and Swift Concurrency both use these tags, meaning there’s more than a decade of developer use and that use will continue into new forms of async logic on the platform. Something that I don’t think can be said about the Win32 environment. So I’m not really sure Apple has incentive to pursue the sort of things Intel/Windows is trying, because they’ve already spent a great deal of effort creating a platform that doesn’t need those things. That tag Apple relies on is the simplest core idea of the semantic information Windows has historically lacked, and they can build on it going forward if they wish.
Yoused
up
- Joined
- Aug 14, 2020
- Posts
- 8,538
- Solutions
- 1
When you are interested in energy efficiency, running 4 or 6 P-cores at BTTW speed is not an issue of hotspots but of memory bandwidth. A starving core still draws power, even waiting for data, so you balance the core clocks against the memory clocks and run them at data transit speed. If I try to drive through the city at 35mph, I will be constantly stopping and starting, wasting fuel the whole time, but if I go 22, I will get there just as fast, with less stress on me and my vehicle.Yeah I don’t know that they could run all cores at 4 though that’d be cool - but @Cmaier talks about how even if total power isn’t too bad, all the cores at full power might interfere with each other and create local hotspots.
Similar threads
- Replies
- 15
- Views
- 2K
- Replies
- 32
- Views
- 4K