You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
macOS 26.2 adds Infiniband over Thunderbolt support
- Thread starter leman
- Start date
Last post on this topic: Apple's CIOMesh with PCC says they use USB 4 predominantly (and sometimes Ethernet) to connect an ensemble of PCC nodes together currently for user requests. I again recommend reading Apple's PCC stuff. It's very very cool! ")
Last edited:
Your point #2 above suggests you are confused.
I was not talking at all about nVidia's GPUs. I was talking about the ConnectX series, now made by nVidia, which comes from their Mellanox acquisition.
As for your point #1: Apple faces a stark choice, because Thunderbolt simply doesn't have the bandwidth for connecting hosts as fast as you want to for scaling out AI (much less scaling up). TB is great compared to 10GbE, but not to 100, much less the 200 used in the DGX Spark, or the 400/800 used in bigger servers.
Putting that speed Ethernet in the Studio would be utterly impractical for the base model. But there's an easy solution. After all, they already make 10GbE optional. It would not be a stretch to make an OSFP or QSFP port with a really fast Ethernet chip behind it an option as well. And if they are supporting a mellanox chip already for their PCC servers, it's reasonable to use those for Studios as well, though there are also several other options. Perhaps Tim Cook has decided it's time to bury the hatchet?
Coming back to your second comment... If you think they're not connecting them with TB, then what do you think they're using? And why wouldn't they consider that tech for the studio, at least as an option?
I can see a much higher speed port like this going on the studio (ultra only) as another differentiator vs. lesser studios and the mini.
Realistically, there's little point including it on lower than the ultra spec due to both available bandwidth/ram and overhead to cluster the things.
Also, as far as I can tell, 128GB RAM per Mac is the minimum to be interesting when clustering Macs to run large models. As of right now, a 128GB Mac costs a minimum of $3500 in Mac Studio form, $4700 in MacBook Pro. These are not consumer Macs! The average Mac owner spent a fraction of those amounts on a base model Mini or Air with at most 16GB RAM. Clustering those together gets you nowhere.
I think you potentially underestimate what hobbyists and small business will perhaps be inclined to spend on low end consumer AI.
Gamers are buying 5090 GPUs, to play games on.
As we move into the AI era, I can easily see somebody spending 5-10k on home AI hardware if it is actually useful and enables them to get such use without a subscription. I've personally got way more than that in apple hardware purchased with my own money in the past 12 months - and I'm nowhere near the upper end of Apple device spending. These are not the "typical" user, but there's certainly a market that does exist for this.
Mac developers / "prosumers" would certainly like to run local AI, especially if it is running Apple trained models for development.
(MacBook Pro m4 max, iPhone 16 pro max, iPad Pro m5, multiple HomePods and other things)...
Please stop scrubbing your comments. You seem very impassioned but you keep doing that and it makes following the conversation difficult. Let’s slow it down a bit and appreciate the intuition and experience of people involved here. I count myself lucky to have such people to chat with, differences of opinion and all.
Last edited:
Again, Feel free to discuss the cool stuff RDMA over Thunderbolt enables for consumer ML, and if so inclined, read and discuss the heavily documented info Apple gave for Private Cloud Compute. I've contributed everything I've could, so I'm ending my part of this post herePlease stop scrubbing your comments. You seem very impassioned but you keep doing that and it makes following the conversation difficult. Let’s slow it down a bit and appreciate the intuition and experience of people involved here. I count myself lucky to have such people to chat with, differences of opinion and all.
Last edited:
- Joined
- Sep 26, 2021
- Posts
- 8,285
- Main Camera
- Sony
Let’s remember that we are all impassioned about one thing or another, and we all have intuition and experience about different things. And with that, let’s focus on substance rather than discussing enthusiasm or credentials.
Thanks!
Thanks!
I think you potentially underestimate what hobbyists and small business will perhaps be inclined to spend on low end consumer AI.
Gamers are buying 5090 GPUs, to play games on.
As we move into the AI era, I can easily see somebody spending 5-10k on home AI hardware if it is actually useful and enables them to get such use without a subscription. I've personally got way more than that in apple hardware purchased with my own money in the past 12 months - and I'm nowhere near the upper end of Apple device spending. These are not the "typical" user, but there's certainly a market that does exist for this.
Mac developers / "prosumers" would certainly like to run local AI, especially if it is running Apple trained models for development.
(MacBook Pro m4 max, iPhone 16 pro max, iPad Pro m5, multiple HomePods and other things)...
Just on this... what I'd consider the upper end of spending... my previous financial director had a bespoke, glossy printed 15 page proposal submitted to kit out his home theatre room.... no idea what he spent, but that's an indication of the scale...

Speaking of the DGX Spark I found this illuminating review from someone who decided to keep theirs and is on the whole positive about it, after all he kept it, though was was fairly candid about the flaws:
He is particularly bullish on the ConnectX-7 port (but which only allows 2 Sparks to connect). The only other advantages I can see over the Mac is CUDA support, Linux/Containerization, and possibly FP4 quantization. Certainly not nothing. However, he keeps mentioning the 128GB unified memory pool ... except the M4 Studio with 546 GB/s bandwidth he mentions can have that too ... so not an advantage at all - at least not relative to the Mac (or the Strix Halo), definitely one relative to standard Nvidia GPUs though. And one has to wonder how the M5 studios will change the calculus here when they arrive.
The one thing that really stood out to me though was this:
When the Project DIGITS was first announced, a bunch of us on the other site were trying to figure out what the specs actually were. Given only the 4bit rating and not knowing if it was Blackwell or Blackwell 2.0, it wasn't easy. In the end, given the size of the device, I concluded the GPU would be much smaller in size, closer to the ratio of FP32 to tensor cores found in server chips. As it turns out I was wrong and those on the other site who argued it would be bigger were right. Nvidia went with a ratio of FP32 to Tensor cores more similar to the consumer Blackwell 2.0 chips so that the GPU's FP32 compute was actually quite sizable, effectively a 5070, but manufactured with the TSMC N3 node - the latter lowering power draw relative the consumer chips still on the older node. They then further lowered power draw by of course using LPDDR instead of GDDR. However, it appears I was still right to question the thermals of effectively putting a 5070 into a chassis that size and trying to cool it effectively even with the better node and LPDDR memory. Apparently not only does the Spark have extreme difficulty maintaining or even reaching mac performance, but also it is reportedly loud to boot. And even with the fixes Nvidia put in recently, its base power levels are quite high.
I wonder why Nvidia felt the need to make it so compact? It's only an inch wider and longer than Mini and I've seen people complain about noise/thermals with the Pro or even base M chip under full load which aren't mean to draw anywhere near 240W. A larger chassis with a bigger cooling system and more airflow would simply have been better (allowing for lager/more numerous and therefore quieter cooling too in addition to being more effective). It doesn't even need to be THAT big. A Studio is still pretty compact. Does anyone know if any of the OEMs have a bigger chassis or just more effective cooling? I know they'll advertise them as such, obviously, and an historical advantage of OEM graphics cards over "Founder" models was cooling, but has anyone seen non-Founder DGX Sparks get tested versus founder models?
Edited: removed FP64, also server Blackwell is also N4P
He is particularly bullish on the ConnectX-7 port (but which only allows 2 Sparks to connect). The only other advantages I can see over the Mac is CUDA support, Linux/Containerization, and possibly FP4 quantization. Certainly not nothing. However, he keeps mentioning the 128GB unified memory pool ... except the M4 Studio with 546 GB/s bandwidth he mentions can have that too ... so not an advantage at all - at least not relative to the Mac (or the Strix Halo), definitely one relative to standard Nvidia GPUs though. And one has to wonder how the M5 studios will change the calculus here when they arrive.
The one thing that really stood out to me though was this:
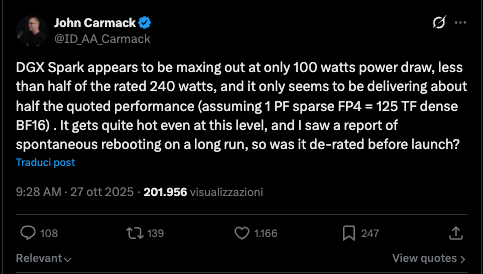
- The thermal design is still aggressive. The 150mm chassis is compact and beautiful, and it still runs hot under sustained load. The February update helps (18W savings when the ConnectX-7 isn’t active), but I still keep a small USB fan pointed at mine. It’s not elegant. It works.
When the Project DIGITS was first announced, a bunch of us on the other site were trying to figure out what the specs actually were. Given only the 4bit rating and not knowing if it was Blackwell or Blackwell 2.0, it wasn't easy. In the end, given the size of the device, I concluded the GPU would be much smaller in size, closer to the ratio of FP32 to tensor cores found in server chips. As it turns out I was wrong and those on the other site who argued it would be bigger were right. Nvidia went with a ratio of FP32 to Tensor cores more similar to the consumer Blackwell 2.0 chips so that the GPU's FP32 compute was actually quite sizable, effectively a 5070, but manufactured with the TSMC N3 node - the latter lowering power draw relative the consumer chips still on the older node. They then further lowered power draw by of course using LPDDR instead of GDDR. However, it appears I was still right to question the thermals of effectively putting a 5070 into a chassis that size and trying to cool it effectively even with the better node and LPDDR memory. Apparently not only does the Spark have extreme difficulty maintaining or even reaching mac performance, but also it is reportedly loud to boot. And even with the fixes Nvidia put in recently, its base power levels are quite high.
I wonder why Nvidia felt the need to make it so compact? It's only an inch wider and longer than Mini and I've seen people complain about noise/thermals with the Pro or even base M chip under full load which aren't mean to draw anywhere near 240W. A larger chassis with a bigger cooling system and more airflow would simply have been better (allowing for lager/more numerous and therefore quieter cooling too in addition to being more effective). It doesn't even need to be THAT big. A Studio is still pretty compact. Does anyone know if any of the OEMs have a bigger chassis or just more effective cooling? I know they'll advertise them as such, obviously, and an historical advantage of OEM graphics cards over "Founder" models was cooling, but has anyone seen non-Founder DGX Sparks get tested versus founder models?
Edited: removed FP64, also server Blackwell is also N4P
Last edited:
The one thing that really stood out to me though was this:
When the Project DIGITS was first announced, a bunch of us on the other site were trying to figure out what the specs actually were. Given only the 4bit rating and not knowing if it was Blackwell or Blackwell 2.0, it wasn't easy. In the end, given the size of the device, I concluded the GPU would be much smaller in size, closer to the ratio of FP32 to tensor cores found in server chips. As it turns out I was wrong and those on the other site who argued it would be bigger were right. Nvidia went with a ratio of FP32 to Tensor cores more similar to the consumer Blackwell 2.0 chips so that the GPU's FP32 compute was actually quite sizable, effectively a 5070, but with the full FP64 and TSMC N3 node of the server Blackwell - the latter lowering power draw relative the consumer chips still on the older node. They then further lowered power draw by of course using LPDDR instead of GDDR. However, it appears I was still right to question the thermals of effectively putting a 5070 into a chassis that size and trying to cool it effectively even with the better node and LPDDR memory. Apparently not only does the Spark have extreme difficulty maintaining or even reaching mac performance, but it is loud to boot. And even with the fixes Nvidia put in recently, its base power levels are quite high.
I wonder why Nvidia felt the need to make it so compact? A larger chassis with a bigger cooling system and more airflow would simply have been better (allowing for lager/more numerous and therefore quieter cooling too). It doesn't even need to be THAT big. A Studio is still pretty compact. Does anyone know if any of the OEMs have a bigger chassis or just more effective cooling? I know they'll advertise them as such, obviously, and an historical advantage of OEM graphics cards over "Founder" models was cooling, but has anyone seen non-Founder DGX Sparks get tested versus founder models?
DGX Spark is supposed to be equivalent to a 5070, and detailed rates can be found in the whitewater: https://images.nvidia.com/aem-dam/S...ell/nvidia-rtx-blackwell-gpu-architecture.pdf
BF16 with FP32 accumulation is expected to run with 1/16 rate compared to sparse FP4 (page 55-55), so there is no discrepancy.
I didn't say there was a discrepancy between BF16 with FP32 and FP4. I was discussing the ratio of standard FP32 versus Tensor core throughput, which as I wrote is indeed the same as the 5070 in the GB10, but which is also different from server Blackwell, which has a higher tensor core throughput relative to standard FP32 compute. And Nvidia didn't originally say off of which, server or consumer Blackwell, they were basing the GB10 GPU. However, it appears my information for FP64 throughput of GB10 being the same as server Blackwell rather than consumer Blackwell 2.0 was out-of-date based on an erroneous entry into techpowerup which has since been corrected:DGX Spark is supposed to be equivalent to a 5070, and detailed rates can be found in the whitewater: https://images.nvidia.com/aem-dam/S...ell/nvidia-rtx-blackwell-gpu-architecture.pdf
BF16 with FP32 accumulation is expected to run with 1/16 rate compared to sparse FP4 (page 55-55), so there is no discrepancy.


So it seems that they took a 5070 design and ported to N3 from N4P (also I had written server Blackwell was N3, which it was not). Though I suppose it is also possible that they took the server design, ported it and then did whatever they do to reduce tensor core and FP64 throughput (which they have substantial control over given the the 5090D variant). Same effect in the end.
Edit: was your note because I said "similar" or "effectively" instead of "identical" when comparing the GB10 and 5070? Sometimes I hedge when I can't remember specific numbers.
Anyway, larger point is ... thermals are bad and I don't know why Nvidia felt the need to make the device and cooling system so small.
Last edited:
I didn't say there was a discrepancy between BF16 with FP32 and FP4.
[…]
Edit: was your note because I said "similar" or "effectively" instead of "identical" when comparing the GB10 and 5070? Sometimes I hedge when I can't remember specific numbers.
Oh, sorry, I was only talking about Carmack’s statement. I guess I quoted too much of your post. Sorry about that. Don’t really have anything to add about the rest.
Maybe just a very quick note since some reading this thread might not be aware: Nvidia recently changed their tensor cores to an outer product design (similar to what Apple does with AMX/SME), which I suppose makes it easier for them to ship different hardware implementations without changing the software model. I can imagine that the server designs use a wider engine. Again, this is entirely orthogonal to the discussion, just a bit of interesting trivia.
Ah got it. I was using Carmack's statement less about the ratio and more about the overall performance throttling which was reportedly repeatable and severe* and apparently is even still not great after the updates.Oh, sorry, I was only talking about Carmack’s statement. I guess I quoted too much of your post. Sorry about that. Don’t really have anything to add about the rest.
*here's another quote in the review about performance from the same time as Carmack's statement:
That post [by Carmack] set off a chain reaction. Tom’s Hardware reported that NVIDIA’s developer forums were flooding with crash reports and unexpected shutdowns under sustained load. ServeTheHome confirmed they couldn’t hit the 240W power ceiling in any workload.
Although I suppose if its not hitting 240W but still hitting max PF/TF that's better ... obviously minus the crashes and the noise ...
Maybe just a very quick note since some reading this thread might not be aware: Nvidia recently changed their tensor cores to an outer product design (similar to what Apple does with AMX/SME), which I suppose makes it easier for them to ship different hardware implementations without changing the software model. I can imagine that the server designs use a wider engine. Again, this is entirely orthogonal to the discussion, just a bit of interesting trivia.
huh that is interesting, thanks!
Last edited:
NotEntirelyConfused
Power User
- Joined
- May 15, 2024
- Posts
- 217
DGX Spark is supposed to be equivalent to a 5070, and detailed rates can be found in the whitewater:
In the... where? Did you take your Spark rafting? Is it IPX7 rated?
In the... where? Did you take your Spark rafting? Is it IPX7 rated?
Apple's autocorrect strikes again! Combine it with an embarrassing dose of dyslexia and funny things will happen