New post from dougallj:
 dougallj.wordpress.com
dougallj.wordpress.com
The post goes into technical details about why Rosetta 2 is an oddity, works well, and what trade offs were made.
I figured especially those of you comparing x86 and ARM would find it very interesting.
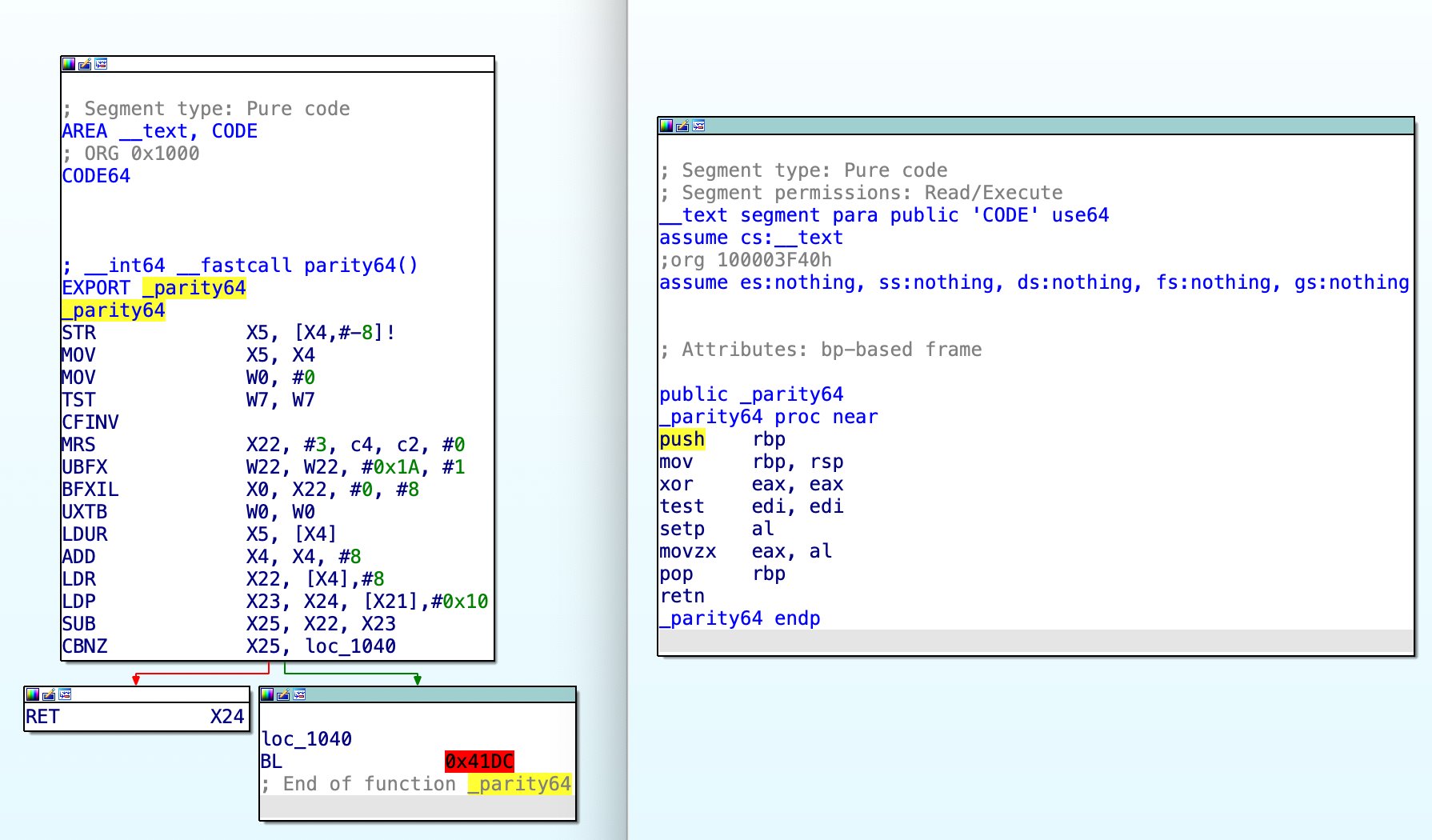
Why is Rosetta 2 fast?
Rosetta 2 is remarkably fast when compared to other x86-on-ARM emulators. I’ve spent a little time looking at how it works, out of idle curiosity, and found it to be quite unusual, so I figur…
dougallj.wordpress.com
The post goes into technical details about why Rosetta 2 is an oddity, works well, and what trade offs were made.
I figured especially those of you comparing x86 and ARM would find it very interesting.
Conclusion
I believe there’s significant room for performance improvement in Rosetta 2, by using static analysis to find possible branch targets, and performing inter-instruction optimisations between them. However, this would come at the cost of significantly increased complexity (especially for debugging), increased translation times, and less predictable performance (as it’d have to fall back to JIT translation when the static analysis is incorrect).
Engineering is about making the right tradeoffs, and I’d say Rosetta 2 has done exactly that. While other emulators might require inter-instruction optimisations for performance, Rosetta 2 is able to trust a fast CPU, generate code that respects its caches and predictors, and solve the messiest problems in hardware.