Just wanted to clarify that my estimate of >25 ns latency was a lower bound for the RAM timing only, so signaling and SoC logic aren't accounted for. I recall that when the Vision Pro was announced, there was vague talk of some kind of packaging tech (sounded like some sort of die to die bonding) that halved the latency between the R1 and RAM. So, to me that means that signaling and such take at least as much time as the RAM timing, meaning that the total latency lower bound for LPDDR5 and A17 Pro would be something like > 50 ns.What matters is the latency as seen by the CPU core. On average it will be nothing close to the RAM timing, because of caches. After all, that‘s the point of caches. So if memory gets 20% faster but your cache hit rate goes down by 40%, you aren’t helping yourself. So I tend to look at the memory subsystem holistically, taking into account page faults, cache misses, the different levels and sizes of cache (each with their own latencies and bandwidth), etc.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Thread: iPhone 15 / Apple Watch 9 Event
- Thread starter exoticspice1
- Start date
- Joined
- Sep 26, 2021
- Posts
- 8,285
- Main Camera
- Sony
Just wanted to clarify that my estimate of >25 ns latency was a lower bound for the RAM timing only, so signaling and SoC logic aren't accounted for. I recall that when the Vision Pro was announced, there was vague talk of some kind of packaging tech (sounded like some sort of die to die bonding) that halved the latency between the R1 and RAM. So, to me that means that signaling and such take at least as much time as the RAM timing, meaning that the total latency lower bound for LPDDR5 and A17 Pro would be something like > 50 ns.
it takes about 6 picoseconds for every millimeter that the signal has to travel.
I've been doing some poking around the iPhone 15 Pro firmware and I've come across something a bit surprising: while the A17 Pro is designated "t8130", one of the firmware images is named
Anyway, a few days ago I was thinking that the A17 Pro and M3 might have been significantly codeveloped because of the new node and new features that are so suitable for laptop and desktop products. This isn't proof, but it's... something? Food for thought, I guess.
sptm.t8122.release.im4p; "t8122" corresponds to the M3 (which would usually be based off the previous generation A SoC, the A16 in this case). Now, this firmware image is for the Secure Page Table Monitor, and is only 99 KB, so it's not exactly a major component. However, I've checked a bunch of other iPhone and Mac firmware (including the A16) and I haven't seen this sort of future product firmware sharing before. Oh, and I've also found some "t8122" references in the DCP (Display Coprocessor) firmware.Anyway, a few days ago I was thinking that the A17 Pro and M3 might have been significantly codeveloped because of the new node and new features that are so suitable for laptop and desktop products. This isn't proof, but it's... something? Food for thought, I guess.
I was thinking more about the controller, amplifiers, logic, etc. rather than the signal propagation speed in copper.it takes about 6 picoseconds for every millimeter that the signal has to travel.
Just discovered TechInsights has a live blog teardown of the 15 Pro (login required). Looking forward to seeing die shots someday!
I wonder when the first M3 devices will be released. Gurman predicts late 2023, Kuo predicts 2024.Maybe it's just the bandwidth. We'll have to wait for M3.
Of course, we're early on, so these crowdsourced scores might change significantly as we get more samples. For instance, they now have the A17 Pro 140 pts lower than it was when you pulled the numbers two days ago.There's also been a PassMark score leak. I know, not ideal. But anyway:
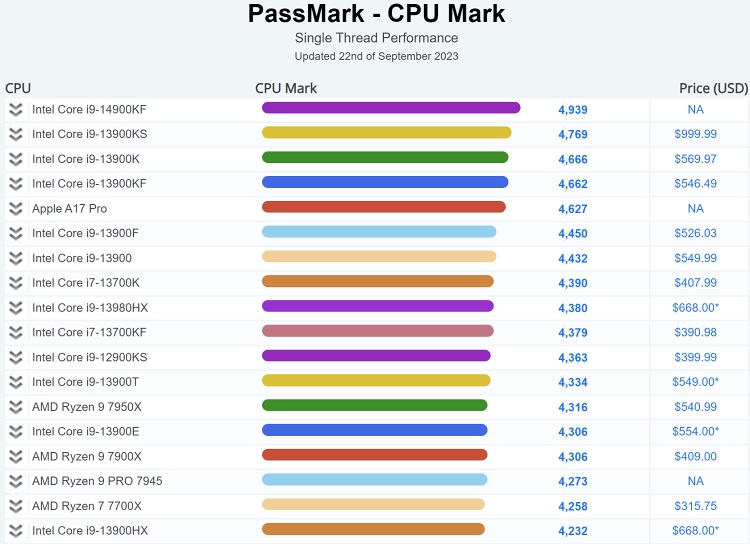
A 3.6% increase after last year's chip. If this leak is accurate, and if this relative increase in PassMark translates to other benchmarks, Apple would retake the single core performance lead with the M3, despite Intel's efforts.
I suspect these crowdsourced scores are underestimates across the board, since only a minority of those submitting them are careful to test under optimum conditions (all other processes off, etc.). So once we get enough data, we're relying on the %underestimate to be approximately device-independent.
Last edited:
Yoused
up
- Joined
- Aug 14, 2020
- Posts
- 8,565
- Solutions
- 1
well, no, I was just being kinda sillyIs there an SVE3?
Coll is an island in Scotland; not sure if that’s consistent enough for you. Seems like a nice spot to me
Regarding memory bandwidth, it’s actually more about memory latency (which I had previously and foolishly dismissed). I’ll try to follow up on that and a couple of other things soon.
@leman Any chance you could share your benchmark code (or alternatively & ideally a TestFlight build)? I think it’d be really interesting to flesh out your plots with the A15, A16, and M2.
I managed to find some free time today and quickly hacked together a simple app. You can find the code here:
GitHub - mr-mobster/AppleSiliconPowerTest: Frequency and power sampling for Apple Silicon computers
Frequency and power sampling for Apple Silicon computers - GitHub - mr-mobster/AppleSiliconPowerTest: Frequency and power sampling for Apple Silicon computers
 github.com
github.com
If some of you want to run this and have results for other chips, please do open an issue on Github and post the results.
Improvements and patches always welcome, of course.
Will add some R code to evaluate the results later.
Andropov
Site Champ
- Joined
- Nov 8, 2021
- Posts
- 753
I opened an issue with the A15 Bionic (iPhone 13 Pro), both normal and low power mode. Btw, do you know what's the oldest OS that could run this?If some of you want to run this and have results for other chips, please do open an issue on Github and post the results.
@Altaic @Andropov I uploaded a new version that improves how testing is done and implements multi-core tests. If any of you can provide some more data points that would be lovely.
 github.com
github.com
I honestly have no idea. It uses private APIs for sampling the performance and power counters, and I don't know where they work and where not. I think Swift 5 is the minimum for the frontend. I suppose one can click though the minimal supported SDK versions and check if it works")
Issues · mr-mobster/AppleSiliconPowerTest
Frequency and power sampling for Apple Silicon computers - Issues · mr-mobster/AppleSiliconPowerTest
github.com
Btw, do you know what's the oldest OS that could run this?
I honestly have no idea. It uses private APIs for sampling the performance and power counters, and I don't know where they work and where not. I think Swift 5 is the minimum for the frontend. I suppose one can click though the minimal supported SDK versions and check if it works
I sure can, though I only have an iPhone 11 Pro, iPhone 12 Pro, iPhone 15 Pro Max, and 16" MBP M1 Max at my disposal, which I believe is the same as you. I'm happy to add my data points if you'd like, though.@Altaic @Andropov I uploaded a new version that improves how testing is done and implements multi-core tests. If any of you can provide some more data points that would be lovely.
Issues · mr-mobster/AppleSiliconPowerTest
Frequency and power sampling for Apple Silicon computers - Issues · mr-mobster/AppleSiliconPowerTest
I sure can, though I only have an iPhone 11 Pro, iPhone 12 Pro, iPhone 15 Pro Max, and 16" MBP M1 Max at my disposal, which I believe is the same as you. I'm happy to add my data points if you'd like, though.
More A14 data would be interesting since my curve currently looks a bit weird.
I've recently come across a couple tidbits from TechInsights.
The first is that one of their iPhone 15 Pros includes LPDDR5 RAM using Micron's "most advanced" D1β process, however Micron had announced this process in Nov 2022 as their LPDDR5X offering which Tom's Hardware expounded on.
The second is that TechInsights published a PDF with die shots (attached), and twitter user Tech_Reve did a quick floor plan from that, which looks basically correct to me (though it's missing a few things). The ANE is on the left hand side in the center and is unlabeled, but is clearly completely redesigned and seems to be a lot smaller even though the claimed perf is much greater. Also, the AMX is right next to the bottom of the ANE and looks identical to the A16's, flipped horizontally. I haven't checked the area calculations, but they seem plausible.

The first is that one of their iPhone 15 Pros includes LPDDR5 RAM using Micron's "most advanced" D1β process, however Micron had announced this process in Nov 2022 as their LPDDR5X offering which Tom's Hardware expounded on.
The second is that TechInsights published a PDF with die shots (attached), and twitter user Tech_Reve did a quick floor plan from that, which looks basically correct to me (though it's missing a few things). The ANE is on the left hand side in the center and is unlabeled, but is clearly completely redesigned and seems to be a lot smaller even though the claimed perf is much greater. Also, the AMX is right next to the bottom of the ANE and looks identical to the A16's, flipped horizontally. I haven't checked the area calculations, but they seem plausible.
Attachments
Eric
Mama's lil stinker
- Joined
- Aug 10, 2020
- Posts
- 15,725
- Solutions
- 18
- Main Camera
- Sony
Finally got around to turning on the new Double Tap feature and have to say it works really well. I know it has multiple uses but where it's been most noticeable for me is when getting a notification, you just double tap your fingers to dismiss it.
Nycturne
Elite Member
- Joined
- Nov 12, 2021
- Posts
- 1,795
Let me know when they offer this as an input:Finally got around to turning on the new Double Tap feature and have to say it works really well. I know it has multiple uses but where it's been most noticeable for me is when getting a notification, you just double tap your fingers to dismiss it.
Jimmyjames
Elite Member
- Joined
- Jul 13, 2022
- Posts
- 1,507
Does anyone have any insight into ray tracing on the A17 Pro? I’ve only seen the 3DMark Solar Bay benchmark and there doesn’t seem to be much uplift from the RT facility there. Only a 50% difference there. The QC gen 3 seems like it’s improved a great deal. I wonder if Solar Bay has to be adapted to take advantage of the rt ability on the A17 Pro?

Chart from here:

 www.notebookcheck.net
www.notebookcheck.net
Chart from here:
Qualcomm Snapdragon 8 Gen 3: First benchmarks and analysis
As part of its Snapdragon Summit in Hawaii, Qualcomm has showcased, amongst other things, its forthcoming top-tier SoC for 2024: the Snapdragon 8 Gen 3. Once again, the CPU cores are getting reorganized, ensuring more performance and we also have the first benchmark results which we would like...
Looks like 1.6x for the QC 2 to 3 vs 1.5x 15 vs 14 for iPhone. Depending on the other intragenerational differences in the GPUs, it doesn’t seem unreasonable.Does anyone have any insight into ray tracing on the A17 Pro? I’ve only seen the 3DMark Solar Bay benchmark and there doesn’t seem to be much uplift from the RT facility there. Only a 50% difference there. The QC gen 3 seems like it’s improved a great deal. I wonder if Solar Bay has to be adapted to take advantage of the rt ability on the A17 Pro?
View attachment 26941
Chart from here:
Qualcomm Snapdragon 8 Gen 3: First benchmarks and analysis
As part of its Snapdragon Summit in Hawaii, Qualcomm has showcased, amongst other things, its forthcoming top-tier SoC for 2024: the Snapdragon 8 Gen 3. Once again, the CPU cores are getting reorganized, ensuring more performance and we also have the first benchmark results which we would like...
Edit: ah gen 2 already had accelerated ray tracing? In that case I’m not sure. One thing they mentioned is that the solar bay is onscreen only.
Jimmyjames
Elite Member
- Joined
- Jul 13, 2022
- Posts
- 1,507
Thanks yeah QC already had it. I think Apple said up to a 4x improvement in ray tracing performance. Being limited to onscreen would change the uplift probably. Weird.Looks like 1.6x for the QC 2 to 3 vs 1.5x 15 vs 14 for iPhone. Depending on the other intragenerational differences in the GPUs, it doesn’t seem unreasonable.
Edit: ah gen 2 already had accelerated ray tracing? In that case I’m not sure. One thing they mentioned is that the solar bay is onscreen only.
Last edited:
Depending on how much the ray tracing was bogging down the scores a 4x uplift could in theory turn into 1.5x for a scene - Amdahl’s law. Having said that if it’s a ray tracing heavy scene which given the name and purpose of the benchmark I would presume it is then yes it seems a little odd. Again the only thing I can think of is offscreen vs onscreen, but otherwiseThanks yeah QC already had it. I think Apple said up to a 4x improvement in ray tracing performance. Weird.

Similar threads
- Replies
- 5
- Views
- 300