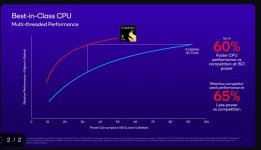
Their claim is "Matches competitor [M2] peak performance at 30% less power" displayed next to a Single Core score comparison. If they are misleadingly hand picking figures from different scenarios and they meant something like "Matches M2 peak performance while using 30% less power during regular use" they may as well say "15% faster than M2 peak performance while using 30% less power", as it looks like it can beat the M2 in single core.
At CineBench 23 the M2 Max was measured to peak at 34-36W [source]. Let's say 40W. And let's use that to get a very conservative upper bound for the M2 core peak power doing: 40W / 8P cores -> 5W/core (it's less, because at least some of those 40W go to the E cores).
Now for the Snapdragon X Elite. If its cores can match the M2 core's performance at 30% less power, that's at most 5W * 0.7 -> 3.5W/core, while matching the scores of a M2 core. The Snapdragon X Elite has 12 cores, so 3.5W * 12 -> 42W total multicore CPU consumption (upper bound) with all cores matching the score of a M2 core.
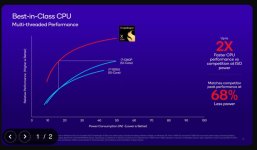
Now let's try to match the above with their other claim "50% faster peak multi-threaded performance vs. M2". The M2 has 4P+4E cores, and we know the E cores reach up to ~25% of the peak performance of the P cores, so the whole CPU has the "combined performance" of 5P cores. However, the Snapdragon X Elite has 12 cores, and each of them should be able to match the performance of a M2 core using 30% less power. Therefore, using just 42W, it should beat the M2 by (12 Snapdragon X Elite cores @ M2 perf level - 5 M2 P cores) / (5 M2 P cores) = 140%. How is it just 50% faster?This is so far off I had to re-check the slides to ensure they weren't talking about M2 Pro/Max.
And it's actually even worse, because the 140% faster projected figure is assuming the CPU can't use more then 3.5W/core (enough to match the M2 core performance). But if, as we know from other figures, the Snapdragon X Elite can reach up to 80W for the CPU alone, and if the "matches M2 peak performance at 30% less power" claim is true, it means that each core should be faster than a M2 core (either that of the performance/power curve goes downwards). And even if it's only a tiny bit faster than the M2 per core at this power, it should destroy the M2 in benchmarks even further, because it has 12 of them.
Strong agree, matches exactly with my own back-of-the-envelope calculations that I alluded to here:
Given what they quoted for single core results, a 12 core Oryon CPU at 50 watts should be closer to 50% faster than a an M2 Max than 50% faster than an M2. That’s a massive discrepancy.
None of this makes any sense to me. I also find the claim that they can use 80% less GPU power for the same performance compared to Ryzen 9 7940HS dubious, I didn't think AMD's GPUs were particularly power hungry, but I don't know much about non-Apple hardware.
We’ve had similar issues with Adreno results in mobile. It seems to get fantastic results in graphics benchmarks with high scores and low power and positively abysmal results in compute given those scores. @Jimmyjames reported the latest results here:
Geekbench Compute for the Adreno 750 (8 Gen 3 Gpu)
12017. Equal to the…A13. Hmmmm
Xiaomi 23116PN5BC - Geekbench
Benchmark results for a Xiaomi 23116PN5BC with an ARM ARMv8 processor.browser.geekbench.com
Seems under Vulcan it matches an A14. Good job.
Xiaomi 23116PN5BC - Geekbench
Benchmark results for a Xiaomi 23116PN5BC with an ARM ARMv8 processor.
Now some of this may be due to the fact that comparing across Geekbench compute APIs is not great and OpenCL is a zombie API on many platforms, but @leman had a theory, backed up by what little he could find about the Adreno GPU that it’s possible that the Adreno GPU effectively fakes its FP32 results in graphics applications and actually runs them as FP16, which doesn’t work in compute applications. I can’t find his post, he might be able to link. The only caveat is that their official FP32 TFLOPs as measured by I can’t remember which program is higher than Apple’s mobile GPU for lower power. If that code is actually enforcing FP32, which it may not be, that wouldn’t be the case under @leman ’s hypothesis. That said, his hypothesis is the only one that makes sense so far and is backed up by the rather poor compute performance. There was another user that likewise suggested Adreno GPUs were somehow specialized for gaming at the expense of compute.
Basically more data/information is needed here. People complain about how little Apple shares but (some due to the time people have spent reverse engineering their stuff) a lot more seems to be known about Apple hardware than Qualcomm’s.
But why would they? Other than the power management unit stuff, I can’t see a reason why they would be forced to clock their cores lower, other than power or heat, and neither should be an issue if its cores are in fact similar to Firestorm.
The final possibility other than being completely misleading is the one that you and I both mooted is that something goes very wrong in feeding the cores in multicore workloads.
Geekbench 6 - Geekbench Blog
www.geekbench.com
"The multi-core benchmark tests in Geekbench 6 have also undergone a significant overhaul. Rather than assigning separate tasks to each core, the tests now measure how cores cooperate to complete a shared task. This approach improves the relevance of the multi-core tests and is better suited to measuring heterogeneous core performance. This approach follows the growing trend of incorporating “performance” and “efficient” cores in desktops and laptops (not just smartphones and tablets)."
Basically, GB5 used to run a separate task on each core, GB6 runs a single multi threaded task across all cores. The former scaled almost perfectly but wasn't representative of typical multi threaded workloads.
Thanks! I could see how that might impact things for many core CPUs - similar to how in a GPU benchmark if you don’t supply a big enough workload some the performance scaling of larger GPUs seems to drop off. But I would hope that 12 single threaded CPU cores wouldn’t be enough to hit that limit in GB6 regardless of how fast they are. Certainly not enough to cause the massive disconnect between single core and multicore values we’re seeing taking all the claims at face value.
Which as @Andropov, @leman, and @Cmaier have all suggested may not be a wise thing to do even beyond standard marketing shenanigans. I’m hoping they confined themselves to standard marketing shenanigans like cherry picking and not something worse.