The article overall seems very good, but there is one part in the CB R24 benchmarking section where I take the opposite view:Chipsandcheese on the Oryon cores:
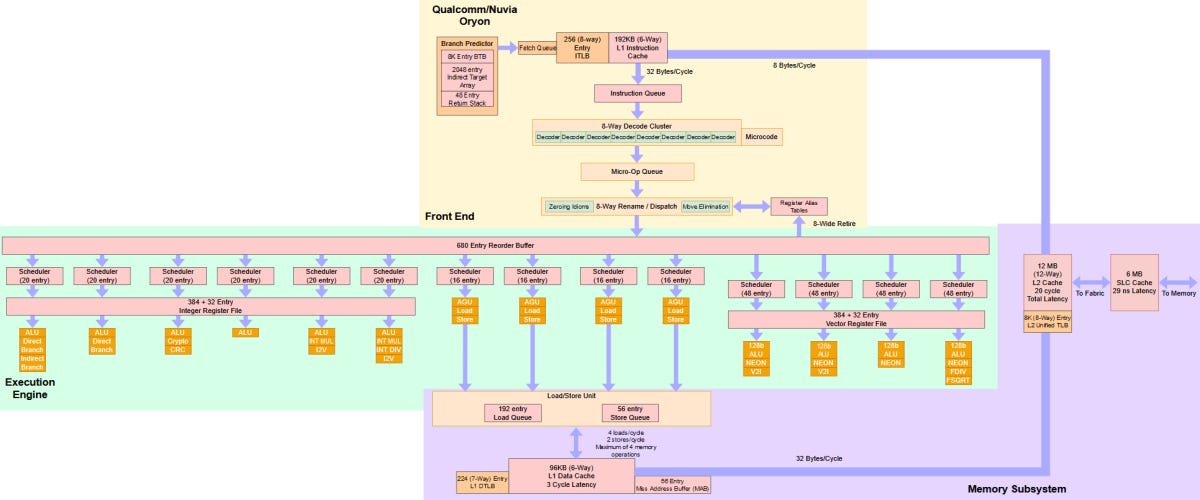
Qualcomm’s Oryon Core: A Long Time in the Making
In 2019, a startup called Nuvia came out of stealth mode.chipsandcheese.com
I haven't had time to read the whole thing yet but given the title of the thread I thought the following snippet might be amusing!
SMT helps AMD by giving each Zen 4 core explicit parallelism to work with. However, that’s not enough to counter the Snapdragon X Elite’s higher core count. The Snapdragon X Elite has 12 cores to AMD’s eight, and comes away with a 8.4% performance lead while drawing just 2% more power. From another perspective though, each Zen 4 core punches above its weight. Qualcomm is bringing 50% more cores to the table, and bigger cores too. Snapdragon X Elite should be crushing the competition on paper, but thermal and power restrictions prevent it from pulling away.
This to me is the wrong way around. Yes each Zen Core punches above its weight ... because as chipsandcheese themselves state in the first sentence each core has two threads. Thus comparing Zen 4 to Oryon, it is 8 to 12 cores but 16 to 12 threads. Each Oryon thread thus punches above its weight and for a test like CB R24 that would be, to my mind, the more relevant metric. The other thing I'm not so sure about is the contention that the Qualcomm cores are bigger. They are "bigger" architecturally, as in a wider design, but my impression is that they are the same physical size or smaller in silicon - like with M1 - in comparison to x86 cores fabbed on the same process. Does anyone know what the sizes actually are?
At any rate I do agree with the last statement though that some of the MT results don't quite match up the paper specs with various possible explanations as to why.
Last edited:


")