Well with say M4 vs M1, if you held clocks constant I’d wager you’re looking at + 17-20% more integer performance and still like probably 40% lower power. Technically the wider arch would use slightly more power so you might have to lower clocks a bit more, but still, that’s all else equal.
Node alone would take you ~ 25-35% down from N5 for the CPU, but the extra L2, newer LPDDR5(x?) and other physical design improvements which we know they’ve seen probably means it’s higher than that in total for the package.
Idk that seems really good to me? Or doing it at similar power and 30% faster even if you don’t notice is still more energy efficient upon the king of energy efficiency.
The E Core improvements are arguably even more important/impressive in some ways
Node alone would take you ~ 25-35% down from N5 for the CPU, but the extra L2, newer LPDDR5(x?) and other physical design improvements which we know they’ve seen probably means it’s higher than that in total for the package.
Idk that seems really good to me? Or doing it at similar power and 30% faster even if you don’t notice is still more energy efficient upon the king of energy efficiency.
The E Core improvements are arguably even more important/impressive in some ways


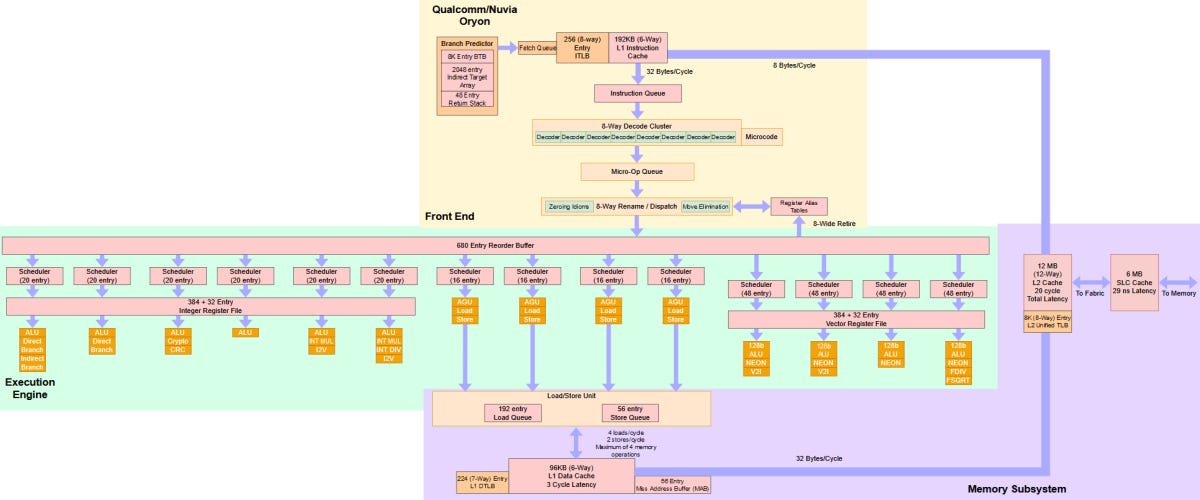
") The section on pipes and decode feels half baked but I don't know how to explain it better without making the post even longer and it is already so long I'm not sure anyone will read it. Obviously if there is anything wrong or something you would disagree with, any corrections would be appreciated.
The section on pipes and decode feels half baked but I don't know how to explain it better without making the post even longer and it is already so long I'm not sure anyone will read it. Obviously if there is anything wrong or something you would disagree with, any corrections would be appreciated.