Noob question. Why is there a need to have the reticle limit limitation? Litho machine cannot project rays that big?Hi. I’m still not quite getting it. The way it works is like this:
View attachment 33116
Each “big” square (containing 49 little squares, in this case) is a reticle.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Apple M5 rumors
- Thread starter dada_dave
- Start date
- Joined
- Sep 26, 2021
- Posts
- 8,283
- Main Camera
- Sony
essentially, yes, you can’t get any yield if you increase the reticle to the size of the wafer, for example. You would need a massive mask, which would have to be perfectly flat (which is harder at bigger dimensions), and the “light” source would have to be much bigger and it gets harder and harder to get the light rays to travel perfectly parallel as you increase size, etc. Just a lot of difficult practical problems. Heck, even data size would be a big problem.Noob question. Why is there a need to have the reticle limit limitation? Litho machine cannot project rays that big?
Yoused
up
- Joined
- Aug 14, 2020
- Posts
- 8,564
- Solutions
- 1
Is there more than one reticle used in a wafer burn, or is it just one mask scanned across each space? (and, does "mask" actually mean a physical thing or is it more like a pattern program setup?) I would guess that they use some kind of assembly-/pipe-line scheme, starting some wafers on the first layer while working on the next layer of ones which have the first layer done, because, otherwise, it is hard to imagine how they could put out a thousand or more multi-layer wafers a day.
- Joined
- Sep 26, 2021
- Posts
- 8,283
- Main Camera
- Sony
it’s one mask, repeated across each space. A mask is a physical thing (one for each layer). The mask is much larger than the reticle, and lenses and such are used to optically reduce it to cause the necessary pattern of light and shadows on the wafer.Is there more than one reticle used in a wafer burn, or is it just one mask scanned across each space? (and, does "mask" actually mean a physical thing or is it more like a pattern program setup?) I would guess that they use some kind of assembly-/pipe-line scheme, starting some wafers on the first layer while working on the next layer of ones which have the first layer done, because, otherwise, it is hard to imagine how they could put out a thousand or more multi-layer wafers a day.
As for pipelining, that is probably still the case. You can’t do all the steps in one machine. You need to apply photoresist in one machine, then do lithography in another, then etch away stuff with another. (at least that was the case when I did fab work. Nowadays they could have crazy machines that do the whole thing, but i doubt it since the hardware to accomplish these steps is quite distinct.
- Joined
- Sep 26, 2021
- Posts
- 8,283
- Main Camera
- Sony
That’s not what I see there. There is an automated carrier system that carries wafers in cartridges from machine to machine. There are different kinds of machines around.
It looks like they might have a setup in which each machine can do several steps without human intervention. Perhaps a single wafer (or batch) can be completed in one of those machines – they just have a lot of them.
The Flame
Power User
- Joined
- Oct 28, 2024
- Posts
- 65
I am guessing Apple M5 will debut Apple's next GPU architecture: Family 10.
Tensor/Matrix cores are one of the probable things that could be added.
Also maybe they'll upgrade from a SIMD architecture to SIMT architecture.
Timestamp = 19:50 of this video contains an explanation about SIMD vs SIMT.
SIMD was first introduced by Nvidia in their Volta GPU architecture in 2017.
AFAIK, Nvidia is the only one doing SIMT. AMD doesn't have it, and Intel doesn't yet (an Intel Representative teased that one of their future GPU architectures will upgrade to SIMT).
Tensor/Matrix cores are one of the probable things that could be added.
Also maybe they'll upgrade from a SIMD architecture to SIMT architecture.
Timestamp = 19:50 of this video contains an explanation about SIMD vs SIMT.
SIMD was first introduced by Nvidia in their Volta GPU architecture in 2017.
AFAIK, Nvidia is the only one doing SIMT. AMD doesn't have it, and Intel doesn't yet (an Intel Representative teased that one of their future GPU architectures will upgrade to SIMT).
Why? Apple already has two different ways to do matrix math, Arm SME (cpu instructions) and Neural Engine (specialized accelerator). I assume that if they feel the need to greatly improve matrix math throughput, they'll scale up the ANE.I am guessing Apple M5 will debut Apple's next GPU architecture: Family 10.
Tensor/Matrix cores are one of the probable things that could be added.
The only reason NV has to put this functionality in the GPU is because in the PC market, that's the only piece of the pie NV makes. Apple gets to build the whole thing, so they have no reason to partition functionality exactly the same way NV does.
Also maybe they'll upgrade from a SIMD architecture to SIMT architecture.
Timestamp = 19:50 of this video contains an explanation about SIMD vs SIMT.
Do you mean 22:00? That's where I found a segment contrasting NVIDIA SIMD and SIMT.
I'm afraid that as far as I can tell, it's a really awful explanation. That video is long on slick animated infographics and gee-whiz narration, but short on accurate technical detail. It tries to imply that SIMT makes execution independent, but what I found by searching the internet for textual descriptions is that NV SIMT is still SIMD, just with lane masking features to emulate independent control flow. (With a substantial performance penalty, but less than if they didn't have the "SIMT" feature.)
The basic idea: instead of a branch, the compiler inserts an instruction to generate a per-SIMD-lane bitmask indicating which ALU lanes want to take the branch, and which ones don't. Whenever the bitmask is a mix of zeroes and ones, both sides of the branch are executed in sequence (not in parallel). While executing the branch-taken code path, the bitmask deactivates lanes that didn't want to take the branch, and vice versa. The bitmask registers are just additional data inputs to the ALUs, so instructions still tell all ALU lanes to do the same thing at the same time, meaning it's still pure lockstep SIMD.
This concept is not at all unique to NVIDIA. It's even found in some CPU SIMD ISAs, such as Intel AVX512, and I'm pretty sure it also exists in other GPUs, probably including Apple's. Other companies may have chosen a better name for it than "SIMT", though. (NVIDIA has an unfortunate habit of using technical terminology in 'interesting' ways that tend to confuse everyone.)
TBH, the better question is when will NVIDIA GPUs get something like Apple Family 9's "Dynamic Cache"?
NotEntirelyConfused
Power User
- Joined
- May 15, 2024
- Posts
- 217
Thanks for sticking with this. Getting close. ")
Each big square contains 7x8=56 little squares. Why don't you want to "shift them over"? If you shifted big-rows 4 and 5 over by 3 little squares, each of rows 4 and 5 would have 7 complete chips instead of 6.Each “big” square (containing 49 little squares, in this case) is a reticle. Reticles near the edge of the circle will be incomplete, of course. In any event, the reticles almost always line up like this (in the real world, anyway) - you don’t want to shift them over as you move from top to bottom, for example. (For various reasons, including making it easier to scribe the wafer, increasing precision of the stepper, etc.)
- Joined
- Sep 26, 2021
- Posts
- 8,283
- Main Camera
- Sony
Thanks for sticking with this. Getting close.
Each big square contains 7x8=56 little squares. Why don't you want to "shift them over"? If you shifted big-rows 4 and 5 over by 3 little squares, each of rows 4 and 5 would have 7 complete chips instead of 6.
well, to start with, it would make it very difficult to saw everything apart, because you’d have a lot of jagged lines instead of a straight shot. Second, you have a stepper that is moving the reticle target from point to point, one step at a time. Quantizing the x-position to a reticle-sized grid makes it much easier for this to be done precisely. Remember, this all has to be done very precisely. After you process all the reticles for, say metal layer 1, you then do some etching and rinsing steps, and put the thing into another stepper to start working on insulator layer 1. This new layer has to line up incredibly precisely with the layer below - a nanometer error is too big an error. A stepper that can move x-wise by fractional amounts is harder to make precise than one that has a single big grid.
This isn’t to say that people haven’t done it before. It’s pretty rare. Intel has a patent on one way to do this: https://patentimages.storage.googleapis.com/53/76/a2/587d1f17505e2b/US8148239.pdf
I doubt they actually do it, but if they do, maybe that explains their fab problems
Adding tensor cores to the GPU makes a lot of sense as it allows the matrix calculations to be utilized during graphics tasks (primarily in denoising) as well as more easily combine with the GPU when both non-matrix and matrix calculations are needed at high throughput without having to share data through the SLC. In the same way that the Neural Engine doesn't just fully replace the SME, adding matrix coprocessors adds a lot of flexibility to where the calculations take place. Apple, even despite not having matrix processors in the GPU yet, recognizes this as their Accelerate framework can choose to send tasks to the GPU instead of the Neutral Engine or SME. Those same tasks can now be accelerated further by the presence of matrix units as well as the additional functionality those matrix units unlock.Why? Apple already has two different ways to do matrix math, Arm SME (cpu instructions) and Neural Engine (specialized accelerator). I assume that if they feel the need to greatly improve matrix math throughput, they'll scale up the ANE.
The only reason NV has to put this functionality in the GPU is because in the PC market, that's the only piece of the pie NV makes. Apple gets to build the whole thing, so they have no reason to partition functionality exactly the same way NV does.
Do you mean 22:00? That's where I found a segment contrasting NVIDIA SIMD and SIMT.
I'm afraid that as far as I can tell, it's a really awful explanation. That video is long on slick animated infographics and gee-whiz narration, but short on accurate technical detail. It tries to imply that SIMT makes execution independent, but what I found by searching the internet for textual descriptions is that NV SIMT is still SIMD, just with lane masking features to emulate independent control flow. (With a substantial performance penalty, but less than if they didn't have the "SIMT" feature.)
The basic idea: instead of a branch, the compiler inserts an instruction to generate a per-SIMD-lane bitmask indicating which ALU lanes want to take the branch, and which ones don't. Whenever the bitmask is a mix of zeroes and ones, both sides of the branch are executed in sequence (not in parallel). While executing the branch-taken code path, the bitmask deactivates lanes that didn't want to take the branch, and vice versa. The bitmask registers are just additional data inputs to the ALUs, so instructions still tell all ALU lanes to do the same thing at the same time, meaning it's still pure lockstep SIMD.
This concept is not at all unique to NVIDIA. It's even found in some CPU SIMD ISAs, such as Intel AVX512, and I'm pretty sure it also exists in other GPUs, probably including Apple's. Other companies may have chosen a better name for it than "SIMT", though. (NVIDIA has an unfortunate habit of using technical terminology in 'interesting' ways that tend to confuse everyone.)
TBH, the better question is when will NVIDIA GPUs get something like Apple Family 9's "Dynamic Cache"?
I have to disagree here too. Don't get me wrong Dynamics cache is awesome, but so is the post-Volta change in forward progress guarantees for Nvidia GPUs and as far as I know no other GPUs besides Nvidia have this capability. The additional factor is not the bit mask but the program counter which allows the scheduler to guarantee that both sides of the branch will eventually execute and avoid deadlocks if you try to do fine-grained parallelism within the warp. (The video is confused in a minor point as Nvidia always called their architecture SIMT, in 2017 Volta they added the "independent scheduling" covered on page 26 and later) I am not as familiar with CPU SIMD. I talked about this more in @Jimmyjames' thread and he linked to the video. There is no evidence in Metal that Apple GPUs are able to do this. However, they have hired some of the Nvidia engineers (Olivier Giroux, the presenter in the video, for one) and some of their patents make oblique references to it. So it is very likely that they will be adding it in the near future.
Last edited:
AFAIK, Nvidia is the only one doing SIMT. AMD doesn't have it, and Intel doesn't yet (an Intel Representative teased that one of their future GPU architectures will upgrade to SIMT).
As so many things in the GPU domain, I am afraid this is another of these stubborn marketing myths. The truth is that Nvidia likes to call their SIMD hardware SIMT. Sure, they have some additional features to improve programmability and efficiency, but so do others.
Nvidia marketing department coined the term "SIMT" back in the day to empathize the programming model that utilizes SIMD to run what looks like single-threaded code. Note that the definition of "thread" differs quite a bit from what is usually considered a thread in CPU land. Later Nvidia had to backtrack a bit as it turns out exposing the underlaying SIMD nature of the hardware can be useful for performance, but they kept the term.
The basic idea: instead of a branch, the compiler inserts an instruction to generate a per-SIMD-lane bitmask indicating which ALU lanes want to take the branch, and which ones don't. Whenever the bitmask is a mix of zeroes and ones, both sides of the branch are executed in sequence (not in parallel). While executing the branch-taken code path, the bitmask deactivates lanes that didn't want to take the branch, and vice versa. The bitmask registers are just additional data inputs to the ALUs, so instructions still tell all ALU lanes to do the same thing at the same time, meaning it's still pure lockstep SIMD.
There are some differences. For example, some GPUs (notably Nvidia) can skip code sections if the thread mask is empty. On a traditional SIMD architecture you'd still run the instructions and discard the results, on Nvidia you don't run them at all. Plus you get additional features like prevention of deadlocks etc., which traditional SIMD does not have. Some argue that these additional features are sufficient to motivate SIMT as an independent architecture type, I tend to disagree — for me this is still just SIMD with some additional optimizations, but that's where we are right now.
Independent thread scheduling is interesting and Nvidia's official explanation of it seems to be rather misleading. This is the relevant patent: https://patents.google.com/patent/US20160019066A1/en
If I understand it correctly, this boils down to adding a new type of barrier that acts as a convergence point for diverging threads. Upon encountering the barrier, the GPU makes sure to run all divergent paths until all relevant threads clear up the barrier. This is what prevents deadlocks and guarantees forward progress within the same warp. Still, this is not magic and it cannot hide the SIMD nature of the hardware. Programmers still need to understand how SIMD divergence works and insert barriers in certain cases to avoid deadlocks.
Why? Apple already has two different ways to do matrix math, Arm SME (cpu instructions) and Neural Engine (specialized accelerator). I assume that if they feel the need to greatly improve matrix math throughput, they'll scale up the ANE.
The GPU is much larger than either CPU or ANE, and it would not be practical to make those large enough. ANE is focusing on low-precision inference, which makes a lot of sense for a specialized unit. AMX is great for low-latency CPU work, but still, it only offers 2TFLOPS of FP32 matmul compute, which is less than what the base M-series GPU can achieve.
I am not sure whether Apple GPUs need a fully featured "tensor" unit, but more throughout as well as support for limited-precision formats would go a long way to improve Apple's reputation for machine learning research.
Oh absolutely and Nvidia talks about that explicitly in the manuals and videos. It’s still SIMD divergence underneath, but it’s also a little more than just barrier underneath (the additional barrier helps force convergence in cases where the programmer might naively expect convergence to naturally happen especially in older Nvidia graphics cards*). The crux of the matter is the program counter and scheduler which tracks how often each thread has been called individually and can interleave their execution to ensure everyone is executed while still grouping active threads together. So yeah Nvidia’s change in terminology to SIMT is far more defensible since the change than before it (which despite my earlier statement to the contrary, one could argue makes the video in @The Flame’s post more accurate than Nvidia’s marketing).Independent thread scheduling is interesting and Nvidia's official explanation of it seems to be rather misleading. This is the relevant patent: https://patents.google.com/patent/US20160019066A1/en
If I understand it correctly, this boils down to adding a new type of barrier that acts as a convergence point for diverging threads. Upon encountering the barrier, the GPU makes sure to run all divergent paths until all relevant threads clear up the barrier. This is what prevents deadlocks and guarantees forward progress within the same warp. Still, this is not magic and it cannot hide the SIMD nature of the hardware. Programmers still need to understand how SIMD divergence works and insert barriers in certain cases to avoid deadlocks.
*side note of a side note: I actually ran into this issue myself. Code which had worked under pre-Volta hardware suddenly stopped working because I was implicitly relying on what Nvidia had made UB (the automatic reconvergence of threads). Even the explicit call to the barrier wasn’t enough as I was communicating between threads in the warp prior to the barrier which I thought was communicating only between active threads, but wasn’t. I went to SO for help with a minimum viable problem code, got the help (from Robert Crovella who informed me of the UB problem and to reread the relevant part of the manual on how to do it right), but unfortunately the mods at SO deleted my post on this as “uninteresting” or some such. Which I thought was a little odd. I mean it was a case of “read the manual more carefully next time”, but I still thought it was subtle enough that others might encounter the same issue.
Last edited:
Oh absolutely and Nvidia talks about that explicitly in the manuals and videos. It’s still SIMD divergence underneath, but it’s also a little more than just barrier underneath (the additional barrier helps force convergence in cases where the programmer might naively expect convergence to naturally happen especially in older Nvidia graphics cards*). The crux of the matter is the program counter and scheduler which tracks how often each thread has been called individually and can interleave their execution to ensure everyone is executed while still grouping active threads together. So yeah Nvidia’s change in terminology to SIMT is far more defensible since the change than before it (which despite my earlier statement to the contrary, one could argue makes the video in @The Flame’s post more accurate than Nvidia’s marketing).
*side note of a side note: I actually ran into this issue myself. Code which had worked under pre-Volta hardware suddenly stopped working because I was implicitly relying on what Nvidia had made UB (the automatic reconvergence of threads). Even the explicit call to the barrier wasn’t enough as I was communicating between threads in the warp prior to the barrier which I thought was communicating only between active threads, but wasn’t. I went to SO for help with a minimum viable problem code, got the help (from Robert Crovella who informed me of the UB problem and to reread the relevant part of the manual on how to do it right), but unfortunately the mods at SO deleted my post on this as “uninteresting” or some such. Which I thought was a little odd. I mean it was a case of “read the manual more carefully next time”, but I still thought it was subtle enough that others might encounter the same issue.
Very interesting, thanks for this! It is a shame your post got deleted, would be interested in reading it.
Very interesting, thanks for this! It is a shame your post got deleted, would be interested in reading it.

CUDA independent thread scheduling
Q1: The programming guide v11.6.0 states that the following code pattern is valid on Volta and later GPUs: if (tid % warpSize < 16) { ... float swapped = __shfl_xor_sync(0xffffffff, val,...
 stackoverflow.com
stackoverflow.com
This one is close enough (and slightly more recent than mine I think so I guess moderators thought this version is okay). My issue was closest to Robert's test case #2 I believe:
C++:
if (tid % warpSize < 16) {
...
float swapped = __shfl_xor_sync(0xffffffff, val, 16);
...
} else {
...
...
}So I was just doing the intra-warp communications on only part of the warp. I thought using active masks (and eventually tried syncing which cause hangs as in test case 3) would be enough but it turns out if the intra-warp communication is part of the divergence things go haywire post-Volta. As Robert explains in hist test case #2 this still runs but gives incorrect results (if I remember right mine was a little different because the shuffles were partially successful, but my memory may be incorrect) - which is the worst one in my opinion for debugging.
EDIT: yeah mine was a little different since it was not just broadcasting from a single lane which could be on the other side of the divergence but from all active lanes communicating with all other active lanes some of which I was implicitly discarding by not doing, so a little different. It worked pre-Volta, but not post-Volta. I essentially reworked the offending code so the shuffle happened outside of the if statement so all active threads in the group participated even when I only wanted some of them.
Last edited:
FWIW, I scanned through ASML's marketing materials for their EUV lithography machine (that's what TSMC uses for all their low-nm processes, since those require EUV, and ASML's are the only EUV litho machines made), and only saw mention of lithography. I'd guess if it could do other stuff they'd say that.
It looks like they might have a setup in which each machine can do several steps without human intervention. Perhaps a single wafer (or batch) can be completed in one of those machines – they just have a lot of them.
CUDA independent thread scheduling
Q1: The programming guide v11.6.0 states that the following code pattern is valid on Volta and later GPUs: if (tid % warpSize < 16) { ... float swapped = __shfl_xor_sync(0xffffffff, val,...
This one is close enough (and slightly more recent than mine I think so I guess moderators thought this version is okay). My issue was closest to Robert's test case #2 I believe:
C++:if (tid % warpSize < 16) { ... float swapped = __shfl_xor_sync(0xffffffff, val, 16); ... } else { ... ... }
So I was just doing the intra-warp communications on only part of the warp. I thought using active masks (and eventually tried syncing which cause hangs as in test case 3) would be enough but it turns out if the intra-warp communication is part of the divergence things go haywire post-Volta. As Robert explains in hist test case #2 this still runs but gives incorrect results (if I remember right mine was a little different because the shuffles were partially successful, but my memory may be incorrect) - which is the worst one in my opinion for debugging.
EDIT: yeah mine was a little different since it was not just broadcasting from a single lane which could be on the other side of the divergence but from all active lanes communicating with all other active lanes some of which I was implicitly discarding by not doing, so a little different. It worked pre-Volta, but not post-Volta. I essentially reworked the offending code so the shuffle happened outside of the if statement so all active threads in the group participated even when I only wanted some of them.
To me all this is very unintuitive. The docs explicitly state that warp shuffle instructions only work for active instructions and that it is undefined behavior to communicate with an inactive thread. The example and Robert's explanation instead suggest that these instructions are an instruction barrier that forces all masked threads to progress regardless of their execution state. I don't see how these two statements can be reconciled in a meaningful way. Also, the definition of synchronization points seems idiosyncratic.
Definitely not an easy programming model. I'd stay away from using these instructions in conditional blocks.
Yeah that's why I thought my issue shouldn't have been deleted by SO even if mine was more of the "standard" case and wasn't the exceptional case brought up in the link, the use of shuffle is pretty nuanced. The programming model I use now to fit a rational mental model is to use the active mask of the cooperative groups API which allows you to call shuffle and then keep that out of any if statements.To me all this is very unintuitive. The docs explicitly state that warp shuffle instructions only work for active instructions and that it is undefined behavior to communicate with an inactive thread. The example and Robert's explanation instead suggest that these instructions are an instruction barrier that forces all masked threads to progress regardless of their execution state. I don't see how these two statements can be reconciled in a meaningful way. Also, the definition of synchronization points seems idiosyncratic.
Definitely not an easy programming model. I'd stay away from using these instructions in conditional blocks.
So something like this:
C++:
if (...){
auto active = coalsced_threads(); //coalesced_threads are only the threads active in the current if statement
auto val = active.shfl(src_val, src_lane); //transfers src_val from src_lane to this thread's val. If source lane is outside the active mask (it can be any thread in the warp, not just from the active mask), undefined behavior
if(...){ }
}That way it makes it clear that only the active threads within the if statement are participating in the shuffle though with the caveat in the comment that it doesn't really protect you from mistakes in ensuring your src_lane is in the active mask. To be fair, if it constrained itself to just the active mask it wouldn't necessarily be clear from a programming model which thread was which from the original warp depending on the if statement.
Yeah that's why I thought my issue shouldn't have been deleted by SO even if mine was more of the "standard" case and wasn't the exceptional case brought up in the link, the use of shuffle is pretty nuanced. The programming model I use now to fit a rational mental model is to use the active mask of the cooperative groups API which allows you to call shuffle and then keep that out of any if statements.
I really like this API and the mental model it constructs (and in fact I wrote a simple version of it for Metal)! However, does it, in its current form solve the issue of thread synchronization? The docs imply that the coalesced threads can change at any time, and it seems that it uses __activemask() under the hood, which does not interact well with independent thread scheduling (e.g. here: https://stackoverflow.com/questions/54055195/activemask-vs-ballot-sync)
So I did, as usual, make a mistake in previous post which I can't edit anymoreI really like this API and the mental model it constructs (and in fact I wrote a simple version of it for Metal)! However, does it, in its current form solve the issue of thread synchronization? The docs imply that the coalesced threads can change at any time, and it seems that it uses __activemask() under the hood, which does not interact well with independent thread scheduling (e.g. here: https://stackoverflow.com/questions/54055195/activemask-vs-ballot-sync)
:Yeah that's why I thought my issue shouldn't have been deleted by SO even if mine was more of the "standard" case and wasn't the exceptional case brought up in the link, the use of shuffle is pretty nuanced. The programming model I use now to fit a rational mental model is to use the active mask of the cooperative groups API which allows you to call shuffle and then keep that out of any if statements.
So something like this:
C++:if (...){ auto active = coalsced_threads(); //coalesced_threads are only the threads active in the current if statement auto val = active.shfl(src_val, src_lane); //transfers src_val from src_lane to this thread's val. [S]If source lane is outside the active mask (it can be any thread in the warp, not just from the active mask), undefined behavior[B][I] - not TRUE!!![/I][/B][/S] if(...){ } }
That way it makes it clear that only the active threads within the if statement are participating in the shuffle though with the caveat in the comment that it doesn't really protect you from mistakes in ensuring your src_lane is in the active mask. To be fair, if it constrained itself to just the active mask it wouldn't necessarily be clear from a programming model which thread was which from the original warp depending on the if statement.
Doing a mask or a cooperative warp group does in fact change the lanes and the active group is indeed only the active group of threads so if it is say the active mask is all even threads, then lane 1 of the active group will warp thread 2. So you are protected from the source lane not being in the active mask but you may have to do the bookkeeping to make sure the lanes in the group you are shuffling from/to are the right ones (the ones you think are shuffling from).
My understanding is that coalsced_threads() is similar to doing something like this:
int mask = __match_any_sync(__activemask(), (unsigned long long)ptr);
So the sync should be covered.
As covered in "Opportunistic Warp-Level Programming" section of the blog post:

Using CUDA Warp-Level Primitives | NVIDIA Technical Blog
NVIDIA GPUs execute groups of threads known as warps in SIMT (Single Instruction, Multiple Thread) fashion. Many CUDA programs achieve high performance by taking advantage of warp execution.
 developer.nvidia.com
developer.nvidia.com
They even say:
Which is found here near the bottom section "Discovering Thread Concurrency" of the blog:
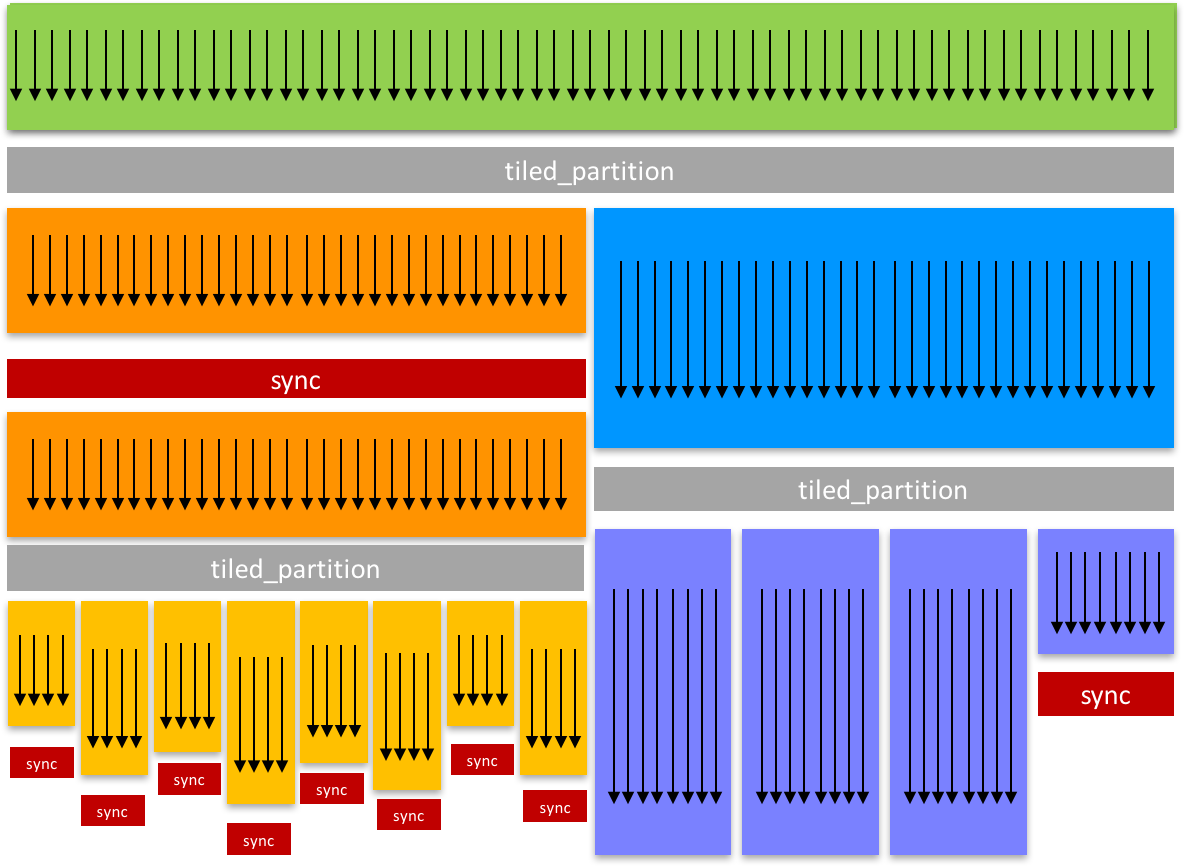
Cooperative Groups: Flexible CUDA Thread Programming | NVIDIA Technical Blog
In efficient parallel algorithms, threads cooperate and share data to perform collective computations. To share data, the threads must synchronize. The granularity of sharing varies from algorithm to…
developer.nvidia.com
Last edited:
Similar threads
- Replies
- 6
- Views
- 545