Hey guys,
Back with another question. This time about Zen5's dual decoders. We see in the diagram that 1T is limited to 4 instructions, is it the same case for M4?
They use very different approaches to decoding. M4 decodes 10 instructions from a single thread per cycle. If I understand Zen4 correctly, it uses the 4-wide decoders to follow different branch paths. It’s a smart way to improve decode performance without introducing too much complexity or added power consumption. Intel went for a more expensive wide decode design.
I still find it hard to imagine how an x86 machine can have 4-wide decoders when one decoder does not know what to work on before the decoder before it finds the instruction boundary.
There are algorithms that exploit parallel hardware to do sequential work. These algorithms operate in multiple stages, with parallel operations that examine individual elements and pass the results to the next parallel stage. It’s just the wider you want to make these things, the more stages and data pipes you need, and the entire thing becomes exponentially more expensive. You can look at sorting networks for a good example. SIMD UTF8 decode is another good one.


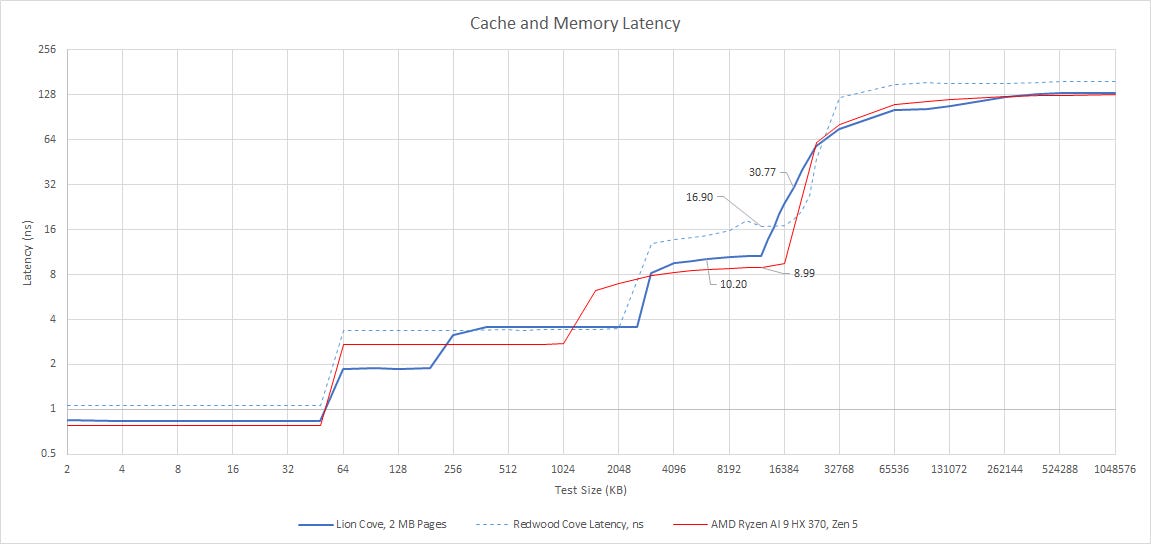

")