Right but they may be changing what kind of threads get assigned where - my impression, you would know better than I, was that there were a bunch of thread levels but only the very bottom were guaranteed to go to the E-cores by default by the scheduler and otherwise Apple would assign threads to an available S-core if possible. Under the hypothesis that the battery life test threads are actually running on the P-core, it's possible that higher priority (though presumably not the highest) threads may be going to the P-core by default, especially on battery but maybe plugged-in too!, instead of the S-core. Basically Apple is starting to shunt threads to the P-cores (even when S-cores are available) to avoid turning on S-core clusters that under the old system would've gone to the S-cores.
There is opportunity here (maybe), but danger as well. To see the latter we need only look at the debacle with Intel's P&E cores in Windows (and even more so AMD's cache++ vs normal cores in 16-core X3D chips).
[Edited to fix flipped P/S in the first two sentences] I think you're probably right - the P cores are probably fast enough that you can put UI stuff on them. If user-interacting threads tend not to give up the CPU until their timeslot expires, then you fire up S cores and migrate them. Would this actually work in practice? I'm not sure. But I think it would, since nobody felt the M1 was laggy, and the new P cores are much faster - nearly the speed of the M3's P cores.
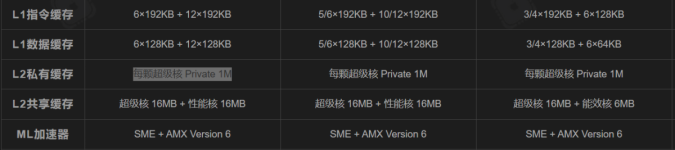
There's another interesting question here, which we can't begin to answer without testing: just how efficient are the P cores? Is it possible that they've achieved a modest breakthrough, to the extent that they can run P cores really slowly to get nearly the performance and efficiency of the old E cores? If that's true, we can expect to see only S and P cores in the future (unless, say, they want a couple of LP cores exclusive to the OS, and they optimize for area and use the E design for that). If it's not, we'll still probably see E cores in at least the A chips, and possibly the base M as well.
My money is on them getting pretty close, or I think they'd have stuck with some E cores, simply because their efficiency is their greatest strength, and I don't think they'd want to dilute it. (This point is really orthogonal to the question of whether they improved their uncore or not.) But I can imagine being wrong - perhaps they see that as capital that might be worth spending to buy something more valuable.
And finally, while this is an obvious one, I just want to empathize that the Fusion Architecture is a cost optimization strategy first and foremost. It's cheaper for Apple to produce two smaller dies and package them together than to manufacture one very large die. Maybe they are going to use it as a performance enhancing strategy as well in the future (e.g. by introducing more GPU cores), but so far that is not what we see.
I'm not so sure about that. Maynard's been arguing over at AT (to little effect, some people there are really incapable of reading) that chiplets aren't so much about cost savings, at least in the general case, as they are about optionality. I don't know enough to disagree, and his arguments seem reasonable - though I think that the tech progress curve ensures that someday that will be wrong. But perhaps not this year, or next.
This may be very much like AMD's situation with EPYCs. For AMD, the overall cost of implementing the entire product line using chiplets is much lower (and it's faster) than using monolithic dies, even though the cost per completed chip is higher using chiplets for the lower-end ones (the higher-end ones couldn't be made with a single monolithic chip). It may be that for Apple, this gives them the ability to make (or at least experiment with) larger aggregations of chiplets, that they really can't justify making as monolithic implementations (or at the high end, like the EPYCs, they won't fit in the reticle size limit). We may see this in the M5 Ultra, or those experiments may never leave their labs in this generation, but we may see their descendants in the M6 or later gens.
")